 Recently I had the following problem: I created an EKS cluster in an AWS account with the root user and could not access the cluster later with other IAM users (with all permissions on EKS) via kubectl.
Recently I had the following problem: I created an EKS cluster in an AWS account with the root user and could not access the cluster later with other IAM users (with all permissions on EKS) via kubectl.
After some research I came across the following paragraph in the AWS documentation:
“You must use IAM user credentials for this step, not root credentials. If you create your Amazon EKS cluster using root credentials, you cannot authenticate to the cluster.”
So I created the cluster again with my IAM user. Now I was able to connect to the cluster (after configuring kubectl as described here: configure kubectl) using my IAM user - but IAM users of colleagues still could not.
In order to authorize further IAM users to use the cluster, the following steps were necessary:
- Gather user or role ARNs
- Create a config.yaml file and insert the presets listed below
apiVersion: v1
kind: ConfigMap
metadata:
name: aws-auth
namespace: kube-system
data:
mapUsers: |
- userarn: arn:aws:iam::<AWS account id>:user/<username of iam user>
username: <username>
groups:
- system:masters
mapRoles: |
- rolearn: <ARN of IAM role>
username: admin:
groups:
- system:masters
- rolearn: <ARN of instance role (not instance profile)>
username: system:node:
groups:
- system:bootstrappers
- system:nodes
system:masters - Allows super-user access to perform any action on any resource. If you want to grant access more granular, please refer to the kubernetes documentation.
The last statement in the mapRoles section must always be present (and configured) in an EKS cluster to allow nodes to join the cluster.
Use the following command to apply the configuration:
kubectl apply -f config.yaml
Using kubectl describe configmap you can validate the current aws-auth configuration
kubectl describe configmap -n kube-system aws-auth
Now the configured IAM users or users holding the defined roles can configure there kubectl pointing to your EKS cluster.
After trying managed Kubernetes cluster on AWS and Google Cloud I have to say that getting started on Google Cloud was quite easier. But after overcoming the start difficulties, EKS works as desired.
If you want to dive deeper into the subject I recommend the following article: EKS and roles
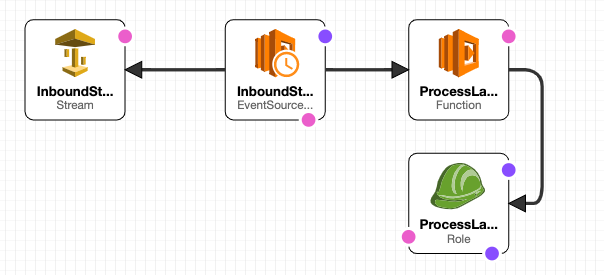


 AWS has released a developer preview of AWS CDK during re:Invent 2018. A detailed description and the release informations can be found here:
AWS has released a developer preview of AWS CDK during re:Invent 2018. A detailed description and the release informations can be found here: